Load & plan
Trigger payload, case record, policy scope, prior steps. Next permitted action within autonomy tier.
The agent run loop, event-driven vs human-initiated triggers, tools vs function calling, and governance checkpoints — the natural follow-up to what agentic AI is.
Reading path: What is agentic AI? → this article → Midlands SME playbook
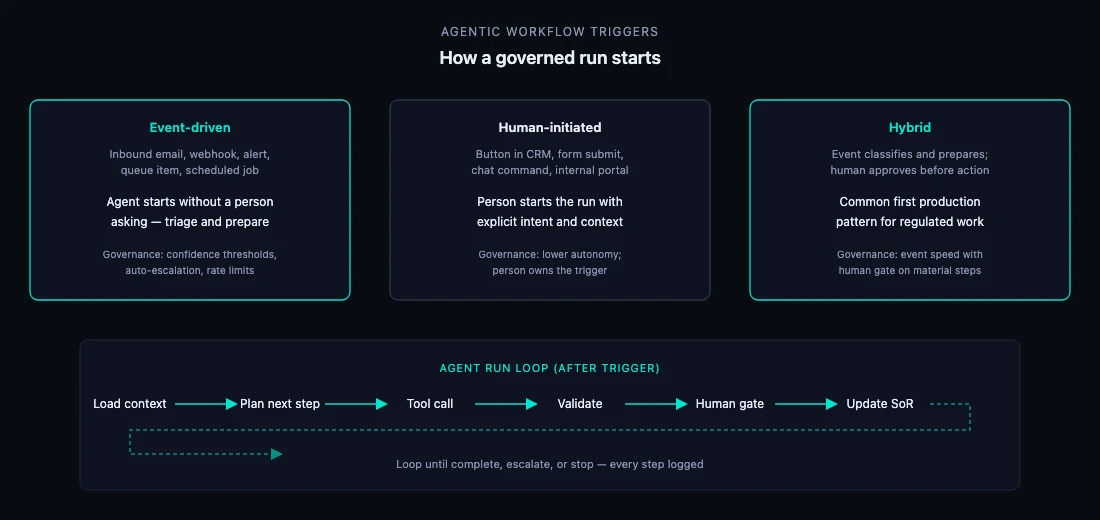
Agentic workflow = trigger → plan and tool use → validation → human gate (where required) → system of record update — with a log of every step.
If you have read what agentic AI is, the next question is operational: how does a run execute inside your business? This article walks the agent loop, trigger patterns, tools vs functions, and governance checkpoints.
An agent does not produce one reply and stop. It executes a bounded loop until completion, escalation, or a defined stop condition.
Trigger payload, case record, policy scope, prior steps. Next permitted action within autonomy tier.
Retrieve data or take action in connected systems — never from model memory alone.
Schema, confidence, policy fit. Mandatory review on material or irreversible actions before commit.
Every iteration logged: tools called, data used, who approved. Stop on low confidence, scope ambiguity, or policy breach.
An agent is software assigned to one goal within a defined boundary — not a product category label.
State lives in a case record — open items, evidence links, approval status — not just chat history.
The first architectural decision — determines autonomy, monitoring, and accountability.
Starts when something happens — inbox email, webhook, queue item, scheduled job.
Person starts the run with intent — CRM button, form submit, “Run assessment” click.
Event prepares work; human approves before material action. Most common for regulated work.
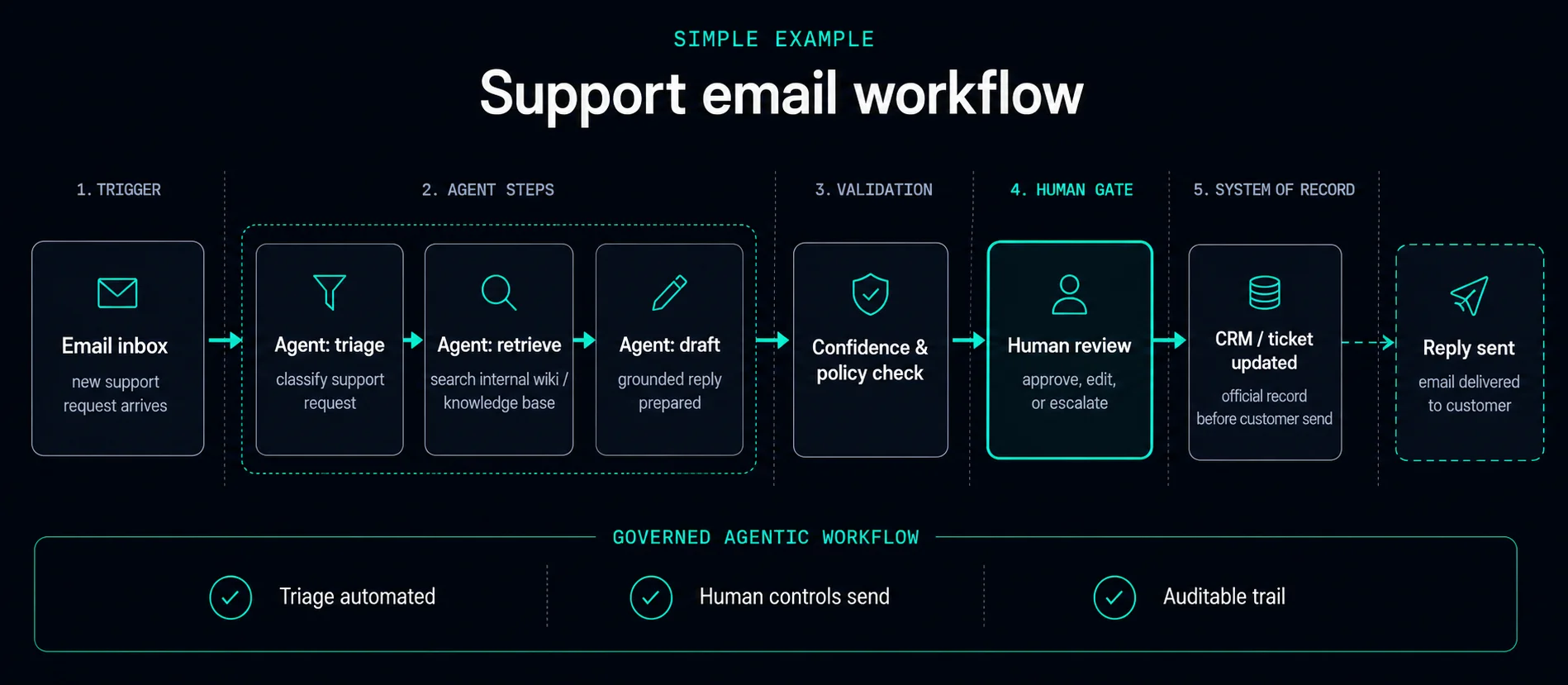
New email → classify intent → search knowledge base and CRM → draft with citations → human gate on low confidence or enterprise accounts → ticket updated in service desk.
Outcome: classified ticket, grounded draft, auditable record — not “the model answered.” Staff retain authority on customer-facing sends.
Bid manager clicks “Draft technical response” for Lot 2, Section 4. Context loads: question text, evaluation criteria, approved past responses, compliance constraints. Tools search the document library and pull certified metrics. Validation checks citations and word limits. Bid manager reviews before export. Draft stored in bid repository with evidence links.
Same loop — different trigger and autonomy. See tender workload measurement and tender response automation.
Function — schema the model may call, e.g. search_policy(query) or create_ticket(title, body).
Tool — governed implementation: auth, scopes, rate limits, validation, audit logging.
Function calling without a tool layer is a demo. With validation, gates, and logging, it is workflow automation.

If nothing authoritative gets updated — or only a spreadsheet sidecar — you have a drafting aid, not an operational workflow.
Customer sends, financial postings, security actions need named accountability — not optional review.
Trigger, tool calls, validation, gate decisions, final state. Incomplete logs fail procurement and audit.
High volume + clear escalation → event or hybrid. High judgment + compliance risk → human-initiated or hybrid.
No case state, gates, or system-of-record writes — does not scale past demos.
Unattended triage without confidence thresholds creates silent failures.
Minimum set for one workflow first; expand after baselines stabilise.
Model-selected calls need schema checks — not blind trust in output format.
Cannot prove improvement without measured “before” performance.
Customer-facing auto-send before autonomy tiers are proven on real traffic.
Pilot shape: Midlands SME playbook · Governance & deployment
Event (email, webhook, schedule), person (button, form), or hybrid where an event prepares work and a human approves.
Function is the callable schema; tool is the governed implementation with auth, limits, validation, and logging.
Yes — load context, plan, tool call, validate, gate, update system of record, repeat until complete or escalated.
Before customer-facing communication, financial commitment, security activity, or irreversible system-of-record updates.
Book a consultation to walk your first agent loop — triggers, tools, validation, and sign-off paths.
Book AI Consultation