Review model
Human approval remains mandatory for customer-facing or financially material actions. Low-confidence outputs route to manual review. Changes are logged to support audit and coaching.
We design workflows to be useful, reviewable, and safe in day-to-day operations. Outputs are treated as assistive recommendations unless explicitly agreed otherwise — with human gates on anything customer-facing, financial, or compliance-sensitive.
Review, content integrity, and measurement — applied consistently across assistants, workflow automation, and multi-agent programmes.
Human approval remains mandatory for customer-facing or financially material actions. Low-confidence outputs route to manual review. Changes are logged to support audit and coaching.
No fabricated claims, relationships, or event references. Only approved data sources and agreed access boundaries. Client tone and policy constraints preserved in generated drafts.
Every pilot tracked against baseline metrics — speed, quality, and outcome indicators. Expansion decisions made on measured performance, not volume of generated output.
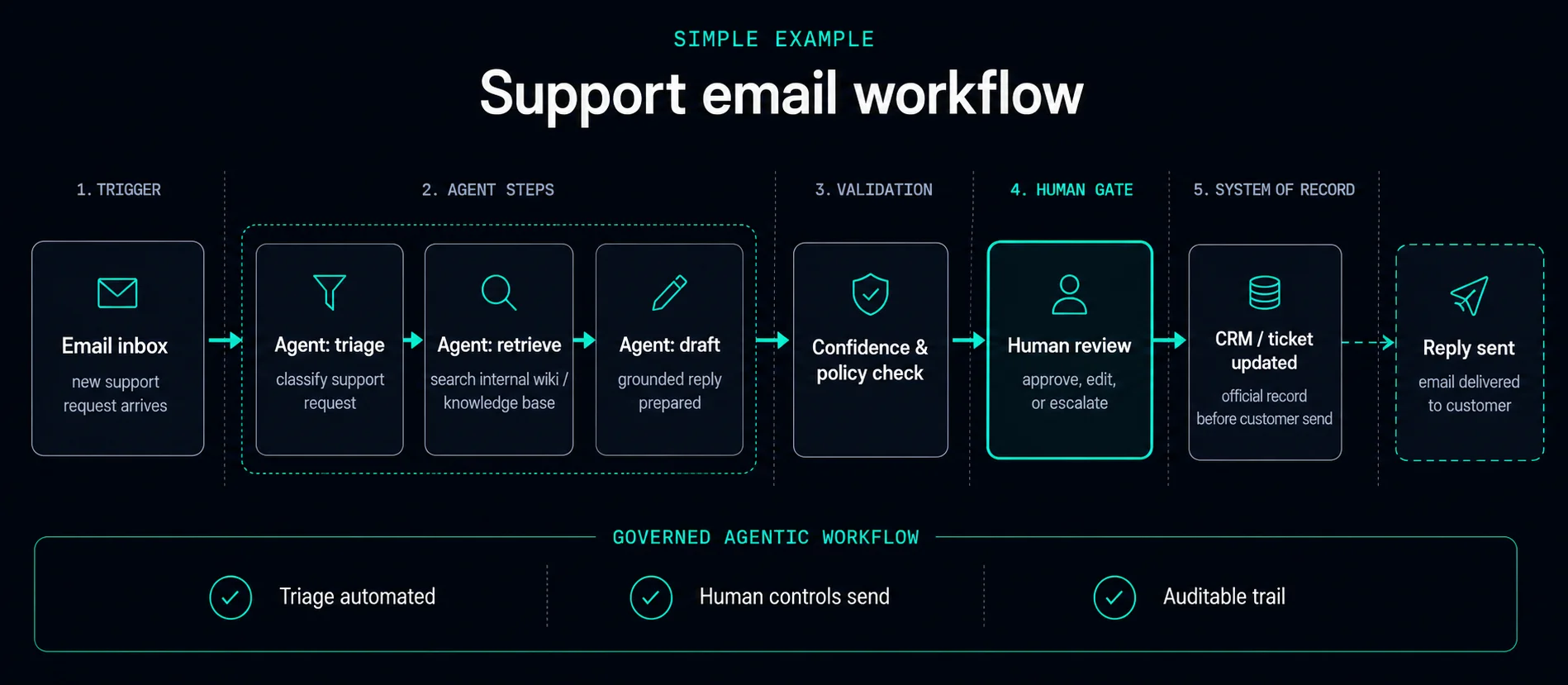
Agents draft, classify, and route — your team approves before anything reaches a customer, ledger, or regulator.
Claims tied to retrievable sources where the domain requires it — bids, compliance packs, and customer comms included.
Low confidence or policy conflict stops the workflow and escalates — rather than guessing and hoping.
Structured logs for runs, tool calls, and human decisions so operations and audit can reconstruct what happened.
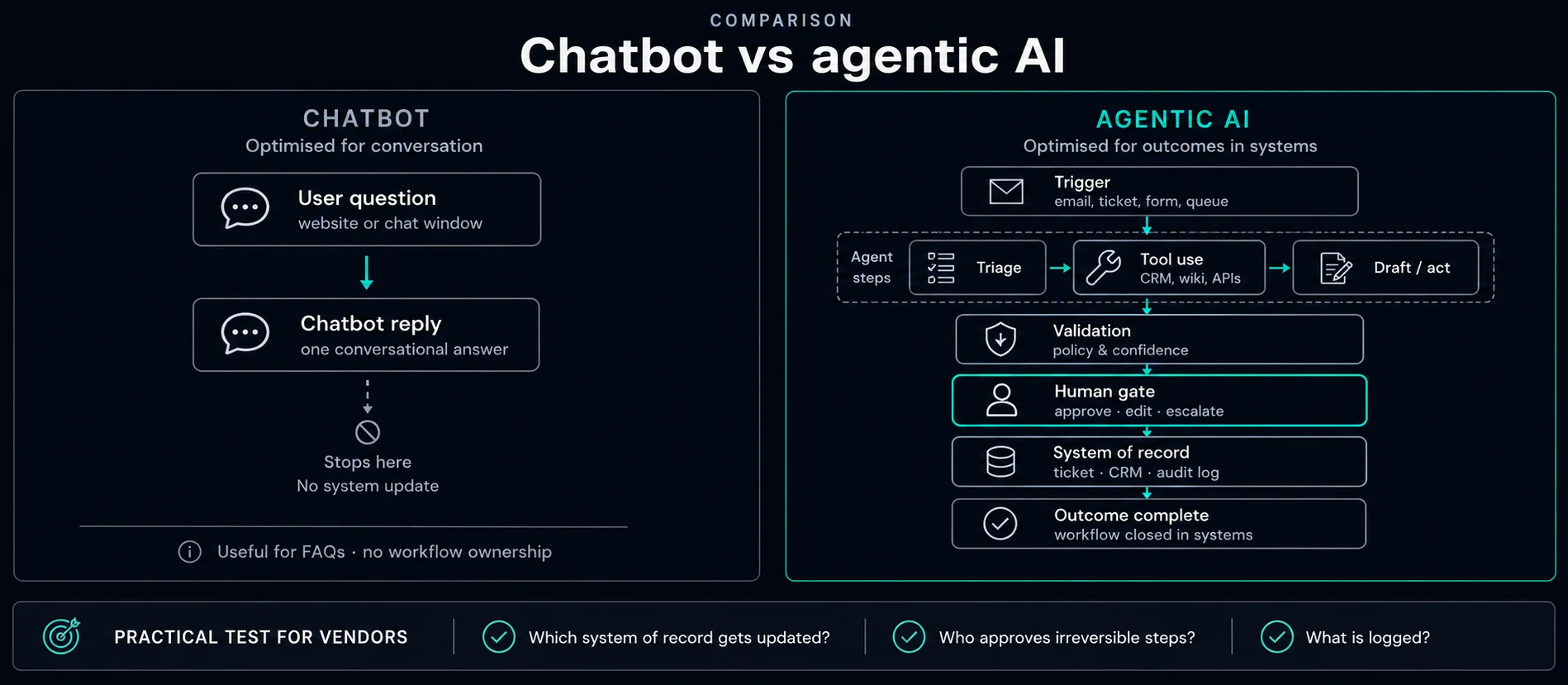
The agent run loop includes explicit checkpoints — not bolted on after the fact. For how triggers, tools, and gates execute in practice, see How agentic workflows run.
Event arrives from email, queue, schedule, or webhook. Intent and risk tier assigned before any outbound action.
Agent retrieves approved sources, drafts the next step, and runs validation rules against policy and confidence thresholds.
High-risk paths pause for explicit approval. Approved actions are logged; rejected paths return to manual handling.
The same review discipline applies whether you are shipping a single assistant or a multi-workflow programme. See how we work for the engagement lifecycle.
Brand guardrails, escalation paths, and approval before any message leaves your environment.
Exception handling, coding, and follow-up workflows with audit trails operations can defend.
Evidence-linked drafts and human review before submission — no unsourced claims in live packs.
Structured evidence collection, gap analysis, and controls suitable for security-conscious buyers.
Baseline discipline, leading vs lagging indicators, and explicit stop rules for month three reviews.
Triggers, tools, validation layers, and human gates in the agent run loop.
Governed workflows, chatbot distinctions, and when orchestration is the right shape.
Evidence collection, gap analysis, and audit-friendly dashboards for SMEs.
Book a consultation to map review gates, data boundaries, and measurement criteria before any build starts.
Book AI Consultation