Volume and cost of delay
Work arrives often enough that shaving minutes per item changes weekly capacity — or errors create rework someone senior has to fix.
The operational playbook for manufacturing, professional services, and logistics teams across Birmingham, Leicester, Wolverhampton, and the wider Midlands. One workflow. Baseline KPIs. A governed 90-day pilot. Scale only where the numbers justify it.
Reading path: What is agentic AI? → How workflows run → this playbook
Most Midlands SMEs we speak to are not asking whether AI matters. They are asking which Tuesday-morning queue is worth fixing first — the shared inbox that never clears, the invoice exception pile sitting in Sage, or the tender pack that absorbs a senior engineer for three days before anyone reviews the numbers.
Agentic AI — systems that plan and execute multi-step work against your tools, not just answer prompts — is still software delivery. Ownership, integrations, and sign-off paths decide success more than model choice. Lean teams across Derbyshire, Leicestershire, and the West Midlands can move faster than enterprises when scope stays narrow and one person can say yes to changing how work is done.
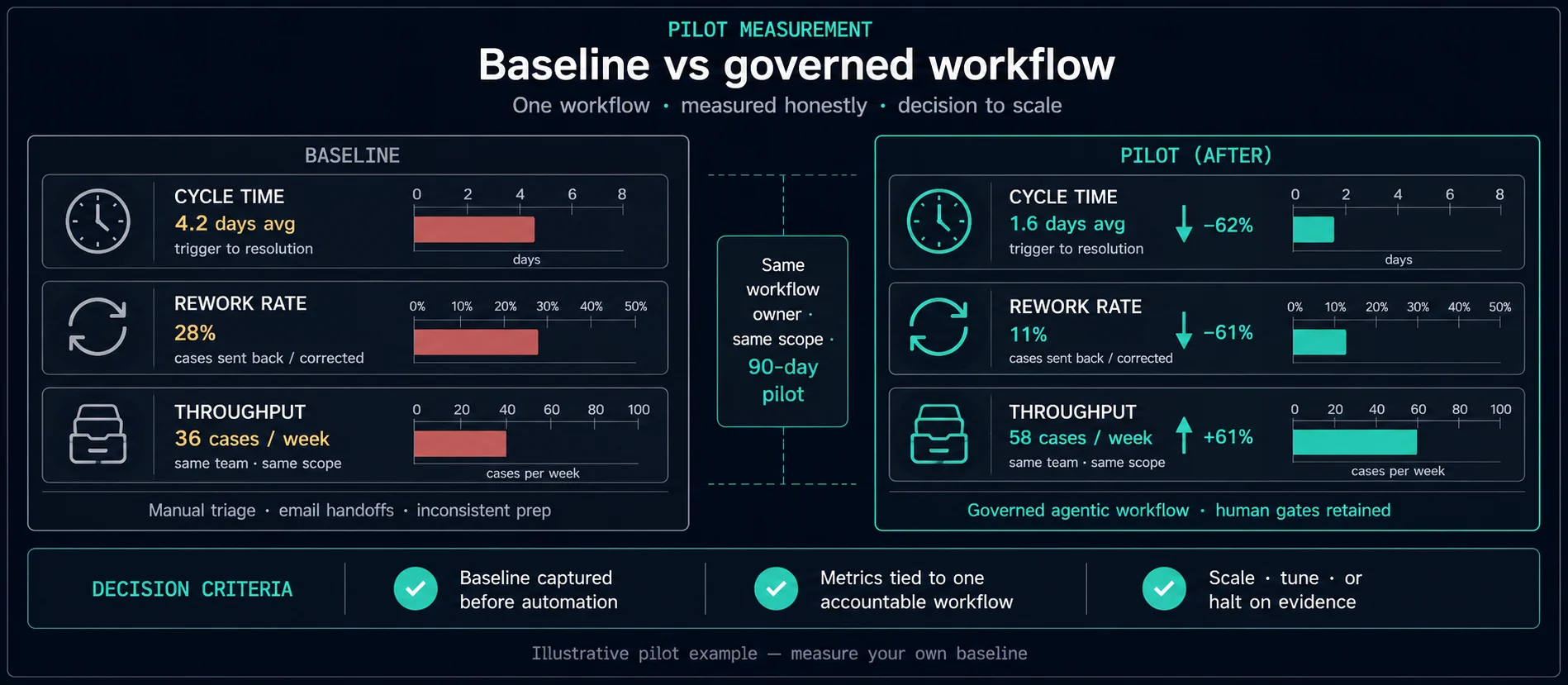
The bet: pick one workflow where delay or error has real cost. Measure baseline performance before you automate. Run side-by-side for at least two representative weeks. Write down who approves exceptions and what gets logged. Stopping is a valid outcome if the KPIs do not move.
For category definitions and mechanics, read What is agentic AI? and How agentic workflows run. This playbook assumes you want the operational sequence: what to pick, how to measure it, and how to survive month three without a slide deck full of unverifiable savings.
Score your candidate workflow against these. If it fails more than one, pick a different queue.
Work arrives often enough that shaving minutes per item changes weekly capacity — or errors create rework someone senior has to fix.
The process can be written down, even if it is messy today. If it changes every week with no owner, fix that before you automate.
There is a place work should land: HubSpot, Sage, Dynamics, a service desk, or a compliance folder — not a parallel spreadsheet nobody trusts.
One person accountable end-to-end who can approve process changes, access integrations, and defend the pilot in a month-three review.
If finance or operations cannot state how long a case takes today, you are not ready to claim savings in week eight. Instrument first.
Pick two or three KPIs leadership already recognises:
Capture baseline across at least a few representative weeks. Seasonality matters for Midlands manufacturers and logistics firms — avoid measuring only a quiet fortnight in August.

The same delivery rhythm we use on client engagements — mapped to a first Midlands SME pilot. Exit criteria at each phase, not open-ended discovery.
Map the workflow on paper. Name the owner. List systems of record (CRM, ERP, M365). Define “good enough” outputs and escalation rules. Agree baseline KPIs and what side-by-side comparison will look like.
Build the smallest integration that processes real traffic — redacted if needed. Run parallel to the old process. Log inputs, tool calls, and human overrides. No auto-send on customer-facing or financial actions until gates are proven.
Compare KPIs to baseline. Tighten evaluation criteria. Train staff on exceptions. Decide scale, refine, or stop — with a written record either way. If you scale, agree permissions and monitoring before volume increases.
The phase cards above are the headline. Below is the operational detail operators ask for on the first call.
Walk the workflow with the person who does it today — not the person who thinks they know how it works. Count triggers: emails per day, exceptions per week, average touches before resolution. Note where people reconstruct context from a twelve-message thread because nothing is in the CRM.
Output: a one-page workflow sketch, a named owner, and a baseline table your FD or ops lead would accept in a management meeting.
Write this down. Examples we use often:
Align with quality standards your team already expects for email and file stores. If you are in a regulated sector, retention and access should match existing policy — not a parallel shadow process.
Run the new path alongside the old one. Same cases, two tracks, compare outcomes. This is slower than a demo. It is also the only honest way to know whether Tuesday’s queue is actually shorter.
Watch for week-four warning signs: integration works on test data but fails on real attachments; staff bypass the tool because it is slower than doing it manually; KPI definitions drift because someone adds “hours saved” nobody measured before.
Leadership will stop asking which model you used. They will ask whether capacity, cost, or risk moved. Bring baseline vs pilot numbers, exception rates, and a clear recommendation: scale, narrow scope, or stop.
Stopping is underrated. A documented “no” on a workflow that did not pay back protects credibility for the next candidate — often finance or tendering, where Midlands SMEs feel the margin pressure first.

Before you sign off on build work — internally or with a partner — confirm the following. Missing items are cheaper to fix in week one than in week seven.
You do not need a large programme office. You do need clear hats:
When IT and the line disagree on access, resolve it in Diagnose — not after the pilot is live. We see this often with shared mailboxes and CRM API limits; both are solvable when someone senior treats it as a priority for two weeks.
Regional patterns from Birmingham, Leicester, Wolverhampton, and wider Midlands engagements — not a sector checklist, but where pilots tend to land when the filters above pass.
Supplier enquiry triage, quality exception logging, tender and PPAP pack preparation with human sign-off on compliance content.
Lead qualification, proposal drafting from discovery notes, SOC 2 evidence collection — where CRM hygiene is good enough to trust retrieval.
Exception queues from TMS or WMS alerts, POD dispute prep, customer status updates with citations to shipment records.
Invoice coding, AP exceptions, credit control chasers, month-end review packs — often the fastest ROI when baselines are already tracked.
Documented patterns: inbound triage · lead qualification · proposal drafting · finance automation · full solutions index
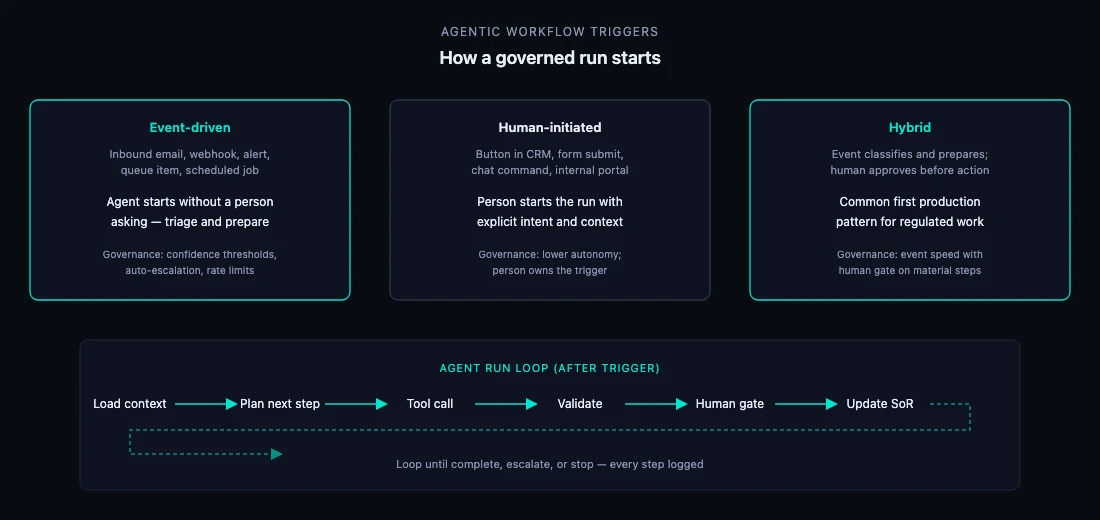
When the pilot works, the hard part is not a bigger model. It is who may trigger autonomous actions, what is logged, how often outputs are spot-checked, and how you roll back on failure.
SME-appropriate controls we implement on engagements:
Deeper deployment practice: AI governance and deployment · agentic AI consultancy.
Rarely the model. Usually ownership, measurement, or integration treated as phase two.
IT, ops, and a vendor each own a slice. No one can change how work is done or defend KPIs in month three.
“Hours saved” appears after automation starts, with no baseline. Finance rightly pushes back.
A chat UI works on sample PDFs. Real invoices from suppliers break the parser on week two.
Triage plus summarisation plus reporting in one scope. None reach production quality.
Auto-send on pricing, credit limits, or compliance statements — until something expensive goes wrong.
Tickets “handled by AI” rise while customer wait time and rework stay flat.
Regional data and ROI context: Agentic AI adoption in the Midlands.
Software that executes multi-step work against your systems with guardrails — not a one-off chat response. Value comes from measurable workflow improvement with a named owner.
Weeks on a narrow scope, framed as 30–60–90 days with side-by-side running and a written stop/go. If integration is clean, you can compress; if data access is slow, do not pretend otherwise.
The ones you already report: time, quality, cost, throughput, or satisfaction — with a baseline captured before automation.
Usually not for a first pilot. You need ownership, system access, and evaluation discipline. Modelling matters when prediction quality is the product.
M365 mailboxes, HubSpot or Salesforce, Sage or Xero, SharePoint — common in Midlands SMEs. One trigger, one system of record, one log destination.
When KPIs do not move after a fair comparison window, integration cost exceeds the friction removed, or quality gates fail without a fix. Document the decision and move on.
Book a consultation to agree baseline KPIs, workflow scope, and governance boundaries before any build starts.
Book AI Consultation